- schema.org, 内部施策・SEO周辺技術
- 更新日:

WebサイトのSEO対策を強化したいと考えているなら、「構造化データ」は欠かせない要素のひとつです。
構造化データを正しく活用することで、検索結果にリッチリザルト(レビュー・FAQ・パンくずリストなど)を表示させることができ、クリック率の向上やユーザー体験の改善にもつながります。
しかし、「そもそも構造化データとは?」「どんな種類や書き方があるの?」と疑問を持つ方も多いのではないでしょうか。
そこで、今回は「構造化データ」について初心者の方でもわかりやすくご紹介します。
また、構造化データを含め、無料のSEO診断を希望される方は下記リンクからお申し込みください。
無料SEO診断、受付中!
「なかなか順位が上がらない…」「今の代理店の対策が正しいか知りたい…」
など、SEO対策でお悩みの方に、50項目以上の無料SEO診断を実施しています。毎月先着10社限定で、経験豊富なSEOコンサルタントが改善のヒントをお届けします!
以下のリンクから、お気軽にお申し込みください!
目次
構造化データとは
構造化データとは、HTMLで書かれた情報を検索エンジンに理解しやすいようにタグづけしたものです。
構造化データが登場するまでの検索エンジンでは、HTMLで書かれた文字列を単なる記号として認識することしかできず、その文字列の意味まで理解することは難しい状況でした。例えば、「デジタルアイデンティティ」という文字列を会社の名前だと判断することは困難でした。
そこで、「デジタルアイデンティティ」を単なる文字列として認識し、蓄積するのではなく、検索エンジンに「デジタルアイデンティティ」は会社の名前であり、所在地は恵比寿であることなどを理解させ、知識として蓄積していこうとする「セマンティックWeb」という考え方が登場しました。
構造化データは、この「セマンティックWeb」という考え方から生まれました。
セマンティックWebとは
先ほどご紹介したように、セマンティックWebとは、検索エンジンに単なる文字列としてテキストを認識させるのではなく、その文字の意味や、文脈、背景などまで理解させようとする考え方です。
セマンティックWebは、World Wide Webの考案者でもあるW3CのTim Berners-Lee氏が提唱したもの。Webの利便性向上を目的に、Web上のデータを検索エンジンが理解できるように意味付けし、検索エンジンがより適切に情報を扱える状態を目指しています。
Googleの検索エンジンは、ミッションとして「世界中の情報を整理し、世界中の人々がアクセスできて使えるようにする」を掲げています。構造化データを用いることは、Googleの検索エンジンのビジョンと一致するのです。
構造化データのメリット
構造化データのメリットは以下の2つが主に挙げられます。
- 検索エンジンがサイトコンテンツを認識しやすくなる
- 検索結果にリッチスニペットが表示されることがある
では、それぞれ詳しくみていきます。
検索エンジンがサイトコンテンツを認識しやすくなる
上述しましたが、構造化データを用いることで検索エンジンはサイトのコンテンツを認識しやすくなります。
適切に記述すると、「デジタルアイデンティティは恵比寿にある会社で、住所は……」といったことまで検索エンジンに認識させることができます。
検索結果にリッチスニペットが表示されることがある
構造化データを用いると、検索結果にリッチスニペットが表示されることがあります。
リッチスニペットとは、下図の赤枠内のことを指します。
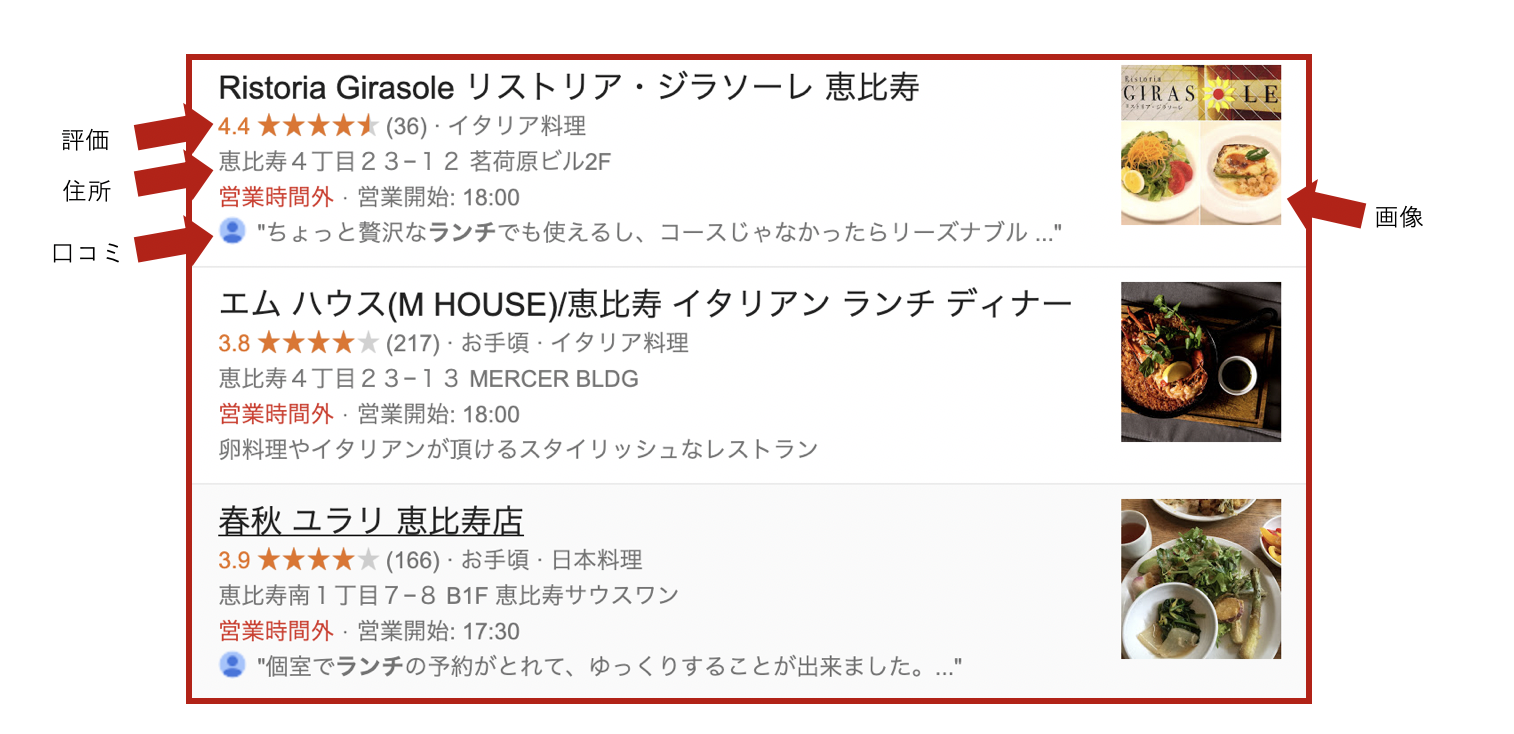
この画像は「恵比寿 ランチ」で検索した結果なのですが、お店の住所や営業時間、口コミなど、詳しい情報が検索結果画面に表示されています。
リッチスニペットは検索結果画面に大きく表示されるので、競合のサイトと差別化が図れたり、ユーザーにクリックされやすくなったりします。
関連:強調スニペットとは?Google検索結果の、やたら目立つアレの話
関連:ナレッジグラフとは?Googleの検索結果にナレッジグラフカードを表示させる方法
また、構造化データには、リッチスニペットの他にも、Googleしごと検索に表示されるようになるといったメリットもあります。
関連:Google しごと検索(Google for Jobs)が日本にもやって来た!~求人業界を変える新機能~
構造化データのデメリット
構造化データのデメリットは、設定に構造化データの知見と作業工数が必要になることです。
場合によってはデザインの変更なども必要になるケースもあります。社内に構造化データに詳しい人材がいれば問題ありませんが、そうでなければ、自力で実装するか外注する必要があります。
コストに見合う価値があるのかは一度吟味すべきでしょう。
構造化データを用いると、検索結果に必ずリッチスニペットが表示されるということではないので、それも含めて「構造化データを用いる必要性」を検討しましょう。
構造化タグの種類
構造化タグといっても、イメージできない方は多いと思います。
構造化タグには、以下のようなものがあります。
※これが全てではありません。
| 構造化タグ | 意味・解説 |
|---|---|
<section> |
見出しを付けられる文章のまとまりであることを示す。 1つの見出し+本文+補足情報で構成される。 |
<article> |
記事であることを示す。 独立した記事やコンテンツであることをします。 ブログでは記事全体が、ニュースサイトではそれぞれのニュース情報が、独立した記事に相当する。 |
<aside> |
補足情報を示す。 本文と関連しているが、区別して掲載するべき補足情報。 本文とは直接関係ないサイドバーにもしようされる。 |
<nav> |
ナビゲーションであることを示す。 グローバルナビゲーションやパンくずリストなどサイト内の主要なページへのリンクに使用 |
<header> |
ヘッダーであることを示す。 導入やナビゲーションの補助であることを示す。 |
<footer> |
フッターであることを示す。 コンテンツ作成者や著作権に関する記述を記載。 その他にも関連文書へのリンクなどの情報を記載できる。 |
これらのタグで文字を囲むと、検索エンジンはその文字の意味を認識しやすくなるわけです。
例えば、sectionタグで囲んだ場合、検索エンジンは「ここからここが文章のまとまりなんだな」と理解しやすくなります。
ボキャブラリーとシンタックスについて
では、ここから構造化データを理解する上で重要になる2つの言葉についてご紹介していきます。
- ボキャブラリー
- シンタックス
簡単に言うと、ボキャブラリーは定義のこと。シンタックスはその記述方法になります。
詳しくみていきます。
ボキャブラリー
ボキャブラリーとは、構造化データを設定する際に、何についての情報なのかを定義するような規格です。
例えば、人の名前だったら”name”を。住所だったら”address”を記述することで、それが人の名前・住所についての情報だということを検索エンジンに伝えます。
現在(2025年3月時点)、Googleがサポートしているボキャブラリーとしては、Google、Yahoo!、Microsoftが策定を進めてきた「schema.org」という規格があります。
このschema.orgでマークアップする際には、タイプとプロパティを指定します。
先ほど例として挙げた、人の名前(タイプ)には”name”(プロパティ)、住所(タイプ)には”address”(プロパティ)を、といった設定もこのschema.orgによって定められています。
会社情報を構造化マークアップする際は、住所や電話番号などを指定してあげるとよいでしょう。
また、「data-vocabulary.org」という規格もありましたが、2020年4月6日をもってサポートを終了するとGoogleがサポートを終了し、マークアップによるリッチリザルト機能の対象外となっています。
参考:データ語彙のサンセットサポート | Google Search Central Blog
なお、Googleはdata-vocabulary.orgの利用者に対し、Google Search Consoleで警告を出し、schema.orgへの移行を促しています。
シンタックス
ボキャブラリーが値を定義しているのに対して、シンタックスは実際にマークアップする際の仕様のことを指します。
シンタックスの中でschema.orgによって定められ、Googleがサポートしているものは以下の3つです。
- Microdata
- RDFa Lite
- JSON-LD
また、この中でGoogleが推奨しているのはJSON-LDです。
JSON-LDは、2014年1月にW3Cの勧告となったオープンデータフォーマットで、スクリプトを用いることで、HTMLのどこにでも記述可能で、かつ1カ所で記述できる仕様になっています。
構造化データの書き方
では、ここからは構造化データの書き方についてご紹介していきます。
構造化データを書く方法は、大きく2つあります。
- HTML上に直接マークアップする方法
- 構造化データマークアップ支援ツールを用いる方法
それぞれ詳しくみていきましょう。
HTML上に直接マークアップする方法
ここでは、先ほどご紹介した以下の3つについてご説明します。
- Microdata
- RDFa Lite
- JSON-LD
Microdata
MicrodataはHTML5から追加され、schema.orgが最初に仕様統一を図ったマークアップ方法であるため、多くのWebサイトに普及しています。
以下はMicrodataによる構造化マークアップの記述例とその説明です。
<body> ・・・ <section itemscope itemtype="http://schema.org/Thing"> <h1 itemprop="name">商品名</h1> <p itemprop="description">商品の概要 <img itemprop="image" src="画像のURL" alt="商品写真"> </section> ・・・ </body>
| 属性 | 意味 |
|---|---|
| itemscope | タグの間にあるHTMLがMicrodataを含んだ要素であることを伝えます。 |
| itemtype | タイプを表すURLを指定します。上記のコード例では、schema.orgの「Thing」が指定されていますが、 他にも「Organization」や「Event」などがあります。 |
| itemprop | プロパティをラベル付けします。上記のコードでは「name」「descripton」「image」が指定されています。 |
MicrodataではHTMLタグやHTML属性を使って定義するため、構造化データと実際のHTMLが一致しやすいといったメリットがあります。しかし、HTML属性が多くなることでHTMLコードが煩雑になりやすく、メンテナンスコストがかかるといったデメリットも存在します。
RDFa Lite
RDFは、セマンティックWebのためにウェブ上のデータに意味を付与する仕組みであり、1999年にW3Cによって規格化されている形式です。そのRDFをXHTMLに埋め込む技術としてRDFaが開発されました。しかし、仕様が複雑だったため、簡素化してMicrodataに似せたものがRDFa Liteです。
以下はRDFa Liteによる構造化マークアップの記述例と、その説明です。
<body> ・・・ <section vocab="http://schema.org/" typeof="Thing"> <h1 property="name">商品名</h1> <p property="description">商品の概要 <img property="image" src="画像のURL" alt="商品写真"> </section> ・・・ </body>
| 属性 | 意味 |
|---|---|
| vocab | 利用する構造化マークアップの規格を定義します。上記のコード例はschema.orgです。 |
| typeof | RDFaのタイプ名を定義します。上記のコード例では、schema.orgの「Thing」が指定されていますが、 他にも「Organization」や「Event」などがあります。 |
| propety | プロパティをラベル付けします。上記のコードでは「name」「descripton」「image」が指定されています。 |
Microdataと比較してみるとわかりやすいのですが、RDFa LiteはMicrodataと類似しています。Microdataとの相違点は、RDFa LiteはXHTMLをベースにしているため、名前空間の拡張が可能である点です。
XHTMLでも使用できるRDFa Liteですが、HTML5が普及する現在では、RDFa Liteはあまり採用されません。後述するマークアップ支援ツールでも扱われていません。
JSON-LD
JSONでは「”キー名”:”値”」形式で、キー名=値の関係を表現します。Microdataと比較してコンピュータが読み取りやすい形式です。
JSON-LDはHTMLファイルのどこに記述しても問題ないのが特徴ですが、一般的にはhead要素内に記述されます。
以下はJSON-LDによる構造化マークアップの記述例と、その説明です。
<head>
・・・
<script type="application/ld+json">
{
"@context" : "http://schema.org/",
"@type":"Thing",
"name":"商品名",
"description":"商品の概要",
"image":"画像のURL"
}
</script>
・・・
</head>
| 属性 | 意味 |
|---|---|
| @context | 利用する構造化マークアップの規格を定義します。上記のコード例はschema.orgです。 |
| typeof | 型名を定義します。上記のコード例では、schema.orgの「Thing」が指定されていますが、他にも「Organization」や「Event」などがあります。 |
| propety | 型のプロパティをラベル付けします。上記のコードでは「name」「descripton」「image」が指定されています。 |
JSON-LDは、Microdata、RDFa Liteと比較して、以下の3点のメリットがあります。
- HTMLソースに影響を及ぼさない
- データを1箇所にまとめて記述するため、システムも人間も読みやすい
- 不可視データのみを記述する際は記述量が少なくて済む(サイズが小さい)
逆に、HTML内のコンテンツを変更する時には必ずJSON-LDも変更する必要があり、適切にメンテナンスしないと、実際のHTMLの内容と構造化データの内容が一致しなくなることがデメリットとして挙げられます。
3形式まとめ
Microdata、RDFa Lite、JSON-LDのメリット・デメリットをまとめたのが、下の図になります。
| 形式 | メリット | デメリット |
|---|---|---|
| Microdata |
|
|
| RDFa Lite |
|
|
| JSON-LD |
|
|
構造化データマークアップ支援ツールを用いる方法
ここまでHTMLファイルに直接記述する方法をご紹介しました。
しかし、中には「難しい」と感じる方も多いのではないでしょうか。
そんな方におすすめなのが構造化データ マークアップ支援ツールを用いて構造化マークアップを行う方法です。
構造化データマークアップ支援ツールを用いると、画面上の簡単な操作だけで、サイトに合わせた構造化マークアップができます。ただ、使えるタイプは一部に限られています。
では、簡単に構造化データマークアップ支援ツールの使い方をご紹介します。
- サイトが該当するジャンルにチェックを入れましょう
- 対象ページを入力
- 「タグ付けを開始」をクリック
- ページが読み込まれたらマークアップしたい部分を選択
- どの項目を定義しているのか選択
以上で、画面右側にマークアップした情報が保存されていきます。
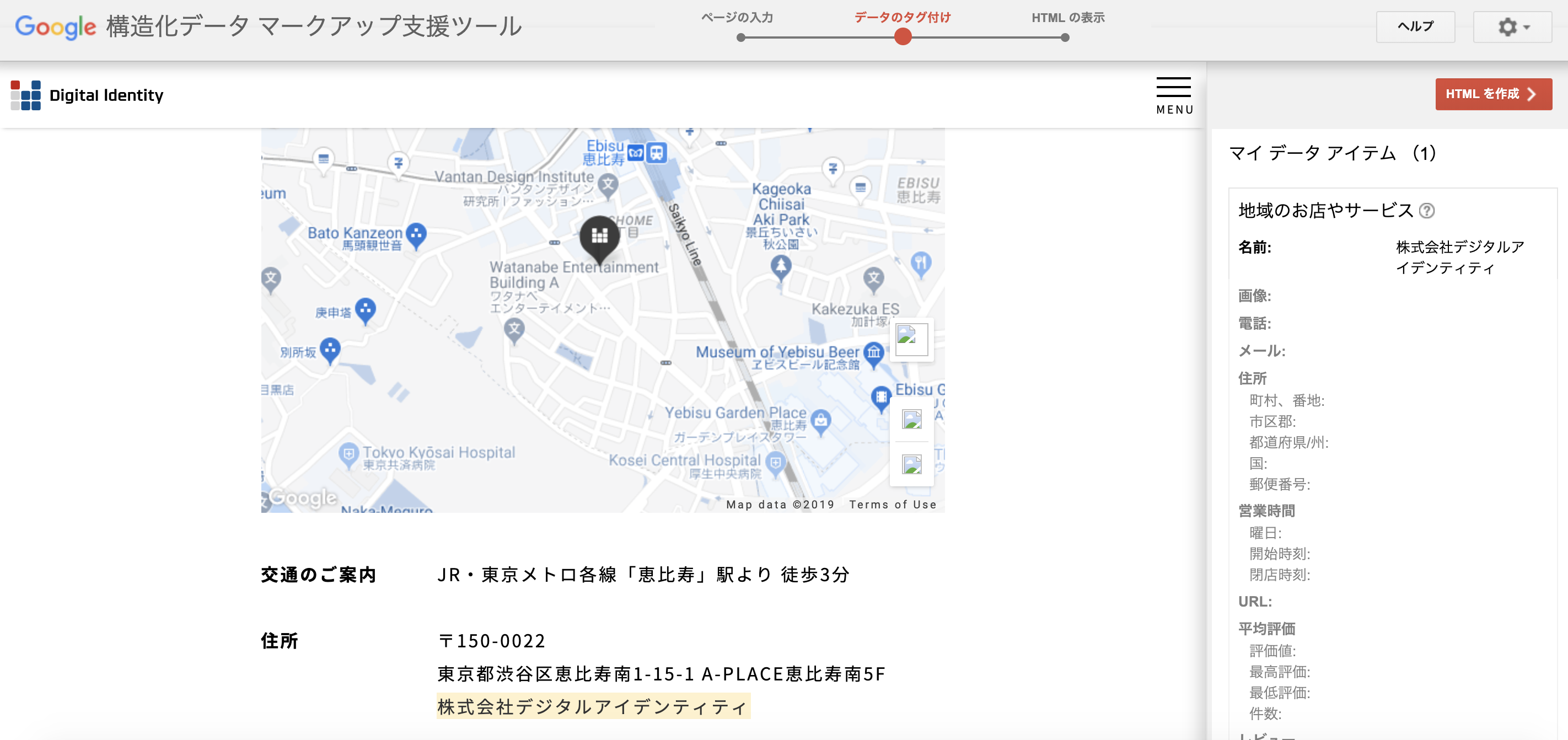
マークアップが完了したら「HTMLを作成」をクリックし、出力されたコードをそのままコピーして、HTMLファイルに貼り付けましょう。また、「ダウンロード」をクリックすればHTMLファイルとしてダウンロードも可能です。
構造化マークアップの記述例
それでは、構造化マークアップの記述例をみていきます。
ここでは、ボキャブラリーはschema.org、シンタックスはJSON-LDを採用した際の以下の2つの構造化マークアップ例をみていきます。
- パンくずリスト
- 求人情報
この他にも、Q&Aページや企業ページなどの構造化マークアップも可能です。
詳しく知りたい方はぜひお問い合わせください。
パンくずリスト
パンくずリストの構造化マークアップの記述例は以下の通りです。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement":
[
{
"@type": "ListItem",
"position": 1,
"item":{
"@id": "URL",
"name": "TOP"
}
}, {
"@type": "ListItem",
"position": 2,
"item":{
"@id": "URL",
"name":"第二階層"
}
}, {
"@type": "ListItem",
"position": 3,
"item":{
"@id": "URL",
"name": "第三階層"
}
}
]
}
</script>
このように記述することで、検索結果にパンくずリストが表示されるようになります。

詳しくは下記の記事でご説明しているので、ご参考にしてください。
関連:JSON-LD+schema.orgで実装するパンくずリストの構造化データマークアップ
求人情報
求人情報の構造化マークアップの記述例は以下の通りです。
<script type="application/ld+json"> {
"@context" : "https://schema.org/",
"@type" : "JobPosting",
"title" : "職種",
"description" : "求人について詳細に説明",
"identifier": {
"@type": "PropertyValue",
"name": "会社名など",
"value": "番号など" },
"datePosted" : "投稿日", //
"hiringOrganization" : {
"@type" : "Organization",
"name" : "会社名",
"sameAs" : "会社HPのURL",
"logo" : "会社ロゴのURL"
},
"validThrough" : "求人有効期限",
"employmentType" : "FULL_TIME:正規雇用 PART_TIME:パート CONTRACTOR:契約社員 TEMPORARY:一時的な社員 INTERN:インターン VOLUNTEER:ボランティア PER_DIEM:日雇い OTHER:その他",
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"streetAddress": "番地",
"addressLocality": ",市区町村等",
"addressRegion": "都道府県",
"postalCode": "郵便番号",
"addressCountry": "国名"
}
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "通貨",
"value": {
"@type": "QuantitativeValue",
"value": 金額, //支払い形式に応じて変更してください。
"unitText": "給与形態:HOUR:時給 DAY:日給 WEEK:週給 MONTH:月給 YEAR:年俸" }
}
}
</script>
このように記述することで、Googleしごと検索(Google for jobs)に求人情報を表示させることができます。
コード不要!データハイライターを用いる方法
構造化データの書き方についてはこれまでご紹介しました。
ただし、HTMLファイルを修正したことない方や、正確にコードを記述できない方は多いでしょう。
しかし、データハイライターというツールを使用すれば、そのような方でも構造化マークアップをすることが可能です。
データハイライターは、構造化データをHTMLに記述しなくても検索エンジンに伝えることができるツールです。
データハイライターの使用手順は、構造化マークアップ支援ツールとほぼ同じです。
サーチコンソールの「検索の見え方」→「データハイライター」→「ハイライト表示を開始」の順に進んでいき、その後、対象ページのURLなどを指示通りに入力します。
データハイライターは、初心者の方でも構造化マークアップを可能にするといった点で、優れています。
しかし、URLに規則性がない場合や、HTMLソースが複雑な場合には、複数ページをまとめてマークアップすることができないといったデメリットもあります。そういった場合、1ページずつマークアップする必要があり、非常に大きな工数がかかってしまいます。
構造化データを検証する方法
構造化マークアップができたら、検証してみましょう。
構造化データの検証には、以下の2つの方法があります。
- 構造化データテストツールを利用する
- サーチコンソールで構造化データを確認する
構造化マークアップを間違えてしまうと、検索エンジンに正しく情報を伝えられないので、検証は必ずするようにしましょう。
構造化データテストツールを利用する
Googleから提供されている構造化データテストツールを用いて検証する方法です。
使い方は簡単で、
- 構造化データテストツールにアクセス
- URLを入力する
- 「テストを実行」をクリック
以上で完了です。
実運用サイトではなく、テスト環境のWebページなど、URLを取得できないページに関しては、「コードスニペット」タブに切り替えて、HTMLコードを入力する必要があります。
テストが実行されたら、画面右側で意図した結果が得られているか、確認しましょう。
詳しく知りたい方はこちらをご覧ください。
関連:構造化データテストツールがバージョンアップ!変更点と使い方
サーチコンソールで構造化データを確認する
Google Search Consoleでも構造化データの設定が正しく行えたか、チェックすることができます。
構造化データテストツールは、1つのURLまたは1つのHTMLコードしか確認できませんが、サーチコンソールは、サイト内の構造化データの設定を一覧で確認することができます。
使い方はこちらも簡単で、サーチコンソールにアクセスした後に、「検索での見え方」から「構造化データ」を選択すれば、確認できるようになっています。
エラーが発生した際はもちろん、Webサイトを更新した際などはサーチコンソールで確認することをおすすめします。
構造化データの設定ミスで検索順位に影響が及ぶことはありません。
しかし、検索エンジンに適切な情報を伝えるという点で、極力エラーのない状態を保つ必要があり、そのためにメンテナンスは重要になります。
まとめ
今回は、構造化データについて詳しくご紹介しました。
構造化データは検索順位に直接は影響しないものの、設定することでコンテンツの内容を検索エンジンに正しく伝えることができます。また、構造化マークアップによって、リッチスニペットが表示されると、ユーザーの目を引くためクリック数に影響を及ぼします。
構造化マークアップをまだしていないという方や企業様がいましたら、ぜひこの機に検討してみてはいかかでしょうか。ツールを使用すれば、初心者の方でも構造化マークアップが可能なので、この記事を参考に試してみましょう。
また、大規模サイトに関しては、幅広いSEO施策が重要です。
大規模サイトのSEO対策に関しては、以下の記事で詳しくご紹介しております。
大規模サイトのSEOは他のサイトとひと味違う?!SEOの基礎と具体策を解説
当サイトではこの他にもWebに関するお役立ち情報を多数ご紹介しています。
Web担当者の方、デジタルマーケティングに興味がある方はぜひご覧ください。
広告運用やSEO、解析・Web製作など、当社はWebに関わるベストソリューションをご提供しています。お悩み・ご相談も受け付けておりますので下記のボタンからお気軽にご連絡ください。
SEOにお困りなら【無料SEO診断】
株式会社デジタルアイデンティティでは、創業から14年以上、SEO対策に注力してきました。
検索エンジンをハックするようなブラックハットな手法に頼ることなく、Googleの推奨に沿ったホワイトハットな手法で上位表示を実現してきました。
そんな弊社のSEOナレッジを50以上の項目に落とし込んだSEO診断を無料でご提供しています!
(毎月先着10社様限定とさせていただいています)

無料SEO診断はこんな方におすすめ!
- SEO対策をどこから始めればいいかわからない…
- 自社でSEO対策をしているが思うように順位が上がらない…
- 他社にSEO対策を依頼しているがセカンドオピニオンが欲しい…
- なぜ競合サイトの検索順位が高いのか知りたい…
- 現在のSEO対策が正しいのか確認したい…
弊社の無料SEO診断でわかること
- 現在のSEO評価
- SEO項目ごとの改善方法
- SEO項目ごとの優先度
正しい現状認識は、SEO対策で効果を出す上で何よりも重要です。
自社のSEO対策について、少しでも気になる方は以下のリンクからお気軽にお申し込みください。





![[無料]成果に繋がる!具体策が分かる!SEOセミナー 「初心者向け」「コンテンツSEO」「サイト内部施策」 詳しくはこちら](https://digitalidentity.co.jp/blog/wp/wp-content/themes/gorgeous_tcd013-child/img/common/bnr/sidebar-seo-seminar.jpg)