- 検索アルゴリズム
- 更新日:


![]()
kobayashiMutsumi
2006年よりSEOコンサルタントとして活躍。デジタルアイデンティティSEO div.manager。金融、不動産、EC、アパレル、通信サービス、人材など業界・業種を問わず経験豊富。プログラマー資格を保有し、クライアントのシステム部と綿密に連携したコンサルティングを得意とする。直近は新規事業立ち上げ、自社メディア運営に携わるなど、組織強化や新規サービス開発にも従事。Google アナリティクス個人認定資格(GAIQ)保有者。
今日はGoogleの「site:」コマンドについてご紹介します。
日々SEOを提案する中で、サイトの調査にあたり様々なツールを使う事がありますが、その中でもシンプルでよく使うコマンドに、Googleの「site:」コマンドがあります!
サイトのwebマスターなら、一度は使った事があると思います。
一見大したツールではないかと思いがちですが、「site:」コマンドを使えば、サイト内の問題点も見つけやすいのです。
SEOmozのサイトで、Googleの「site:」コマンドのオプションという記事がアップされていたので、おさらいも兼ねて記載したいと思います。
25 Killer Combos for Google’s Site: Operator | SEOmoz
2013/1/24 記載者:Dr. Pete
「site:」について知らない方は参考にして頂ければと。
概ね翻訳していますが、見解も含め抜粋しておりますので、その点はご了承下さい。
無料SEO診断、受付中!
「なかなか順位が上がらない…」「今の代理店の対策が正しいか知りたい…」
など、SEO対策でお悩みの方に、50項目以上の無料SEO診断を実施しています。毎月先着10社限定で、経験豊富なSEOコンサルタントが改善のヒントをお届けします!
以下のリンクから、お気軽にお申し込みください!
目次
- 1 「site:」コマンドオプション一覧表
- 2 1. site:example.com
- 3 2. site:example.com/folder
- 4 2. site:example.com/folder
- 5 3. site:sub.example.com
- 6 4. site:example.com inurl:○○
- 7 5. site:example.com -inurl:○○
- 8 6. site:example.com -inurl:○○ -inurl:△△ -inurl:××
- 9 7. site:example.com inurl:https
- 10 8. site:example.com inurl:param
- 11 9. site:example.com -inurl:param
- 12 10. site:example.com テキスト
- 13 11. site:example.com “テキスト”
- 14 12. site:example.com/folder “テキスト”
- 15 13. site:example.com this OR that
- 16 14. site:example.com “top * ways”
- 17 15. site:example.com “top 5..40 ways”
- 18 16. site:example.com ~word
- 19 17. site:example.com ~word -word
- 20 18. site:example.com intitle:”テキスト”
- 21 19. site:example.com intitle:”text * here”
- 22 20. intitle:”テキスト”
- 23 21. “テキスト” -site:example.com
- 24 22. site:example.com intext:”テキスト”
- 25 23. site:example.com “テキスト” -intitle:”テキスト “
- 26 24. site:example.com filetype:pdf
- 27 25. site:.edu “テキスト”
- 28 「site:」コマンドを使用する際の注意点
- 29 SEOにお困りなら【無料SEO診断】
「site:」コマンドオプション一覧表
記事の本文に入る前に今回ご紹介する「site:」コマンドオプションの一覧表を掲載しておきます。
コマンドの中に()がある部分は任意の文字列を指定可能な箇所です。
詳しく知りたい方は「解説はこちら」をクリックすると、該当コマンドを詳しく紹介している見出しに飛べます。
| 番号 | コマンド | 解説 | |
|---|---|---|---|
| 1 | site:example.com | 基本の使い方。該当URLを含むページリストを表示 | 解説は こちら |
| 2 | site:example.com/(folder) | 特定のサブフォルダを含むページリストを表示 | 解説は こちら |
| 3 | site:sub.example.com | 特定のサブドメインを含むページリストを表示 | 解説は こちら |
| 4 | site:example.com inurl:○○ | URL内に「○○」の文字列を含むページを表示 | 解説は こちら |
| 5 | site:example.com -inurl:○○ | URL内に「○○」の文字列があるページを除外して表示 | 解説は こちら |
| 6 | site:example.com -inurl:○○ -inurl:△△ -inurl:×× | 条件の組み合わせ。「○○」「△△」「××」の文字列を除外 | 解説は こちら |
| 7 | site:example.com inurl:https | 「https:」で暗号化されたページのみを表示 | 解説は こちら |
| 8 | site:example.com inurl:(param) | 特定のパラメータを含むページを表示 | 解説は こちら |
| 9 | site:example.com -inurl:(param) | 特定のパラメータを含むページを除外して表示 | 解説は こちら |
| 10 | site:example.com (テキスト) | コンテンツに「テキスト」を含む、または関連するページを表示 | 解説は こちら |
| 11 | site:example.com “(テキスト)” | 「テキスト」にマッチするコンテンツのあるページを表示 | 解説は こちら |
| 12 | site:example.com/folder “(テキスト)” | 特定のサブフォルダ内で「テキスト」にマッチする コンテンツのあるページを表示 |
解説は こちら |
| 13 | site:example.com (this) OR (that) | 「this」または「that」を含む、または関連するページを表示 | 解説は こちら |
| 14 | site:example.com “(top) * (ways)” | top * waysの並びの文字列を含むページを表示。 *は正規表現で任意の1文字or複数文字 |
解説は こちら |
| 15 | site:example.com “(top) 5..40 (ways)” | 14の正規表現部分を任意の数字範囲に変更したもの(例は5〜40) *は正規表現で任意の1文字or複数文字 |
解説は こちら |
| 16 | site:example.com ~(word) | 指定した「word」と関連するキーワードを含むページを表示 | 解説は こちら |
| 17 | site:example.com ~(word) -(word) | 指定した「word」と関連するキーワードを除外したページを表示 | 解説は こちら |
| 18 | site:example.com intitle:”(テキスト)” | タイトルに「テキスト」の文字列を含むページを表示 | 解説は こちら |
| 19 | site:example.com intitle:”(text) * (here)” | タイトルの文字列検索に14の正規表現を組み合わせたもの *は正規表現で任意の1文字or複数文字 |
解説は こちら |
| 20 | intitle:”(テキスト)” | 「テキスト」のタイトルがあるページを外部サイトを含めて表示 intitle単独でも使用可能 |
解説は こちら |
| 21 | “(テキスト)” -site:example.com | 該当URL以外で「テキスト」を含むページを表示 | 解説は こちら |
| 22 | site:example.com intext:”(テキスト)” | 本文に「テキスト」を含むページを表示 | 解説は こちら |
| 23 | site:example.com “(テキスト)” -intitle:”(テキスト)” | 本文に「テキスト」を含み、タイトルには含まないページを表示 | 解説は こちら |
| 24 | site:example.com filetype:(pdf) | ファイル拡張子が「pdf」であるページを表示。 「jpg」「png」「xls」など任意の拡張子を指定可能 |
解説は こちら |
| 25 | site:.(edu) “(テキスト)” | トップレベルドメインを指定して「テキスト」を含むページを表示。 「.jp」「.com」なども指定可能 |
解説は こちら |
1. site:example.com
コマンドの組み合わせじゃないけれど、知らない方はまずここから!
ルートドメイン、又はサブドメインを「site:」の後ろに記述して検索すると、ドメインのインデックスされているページ数をGoogleが概算で返してくれます。
“概算で”という部分に関しては後述します。
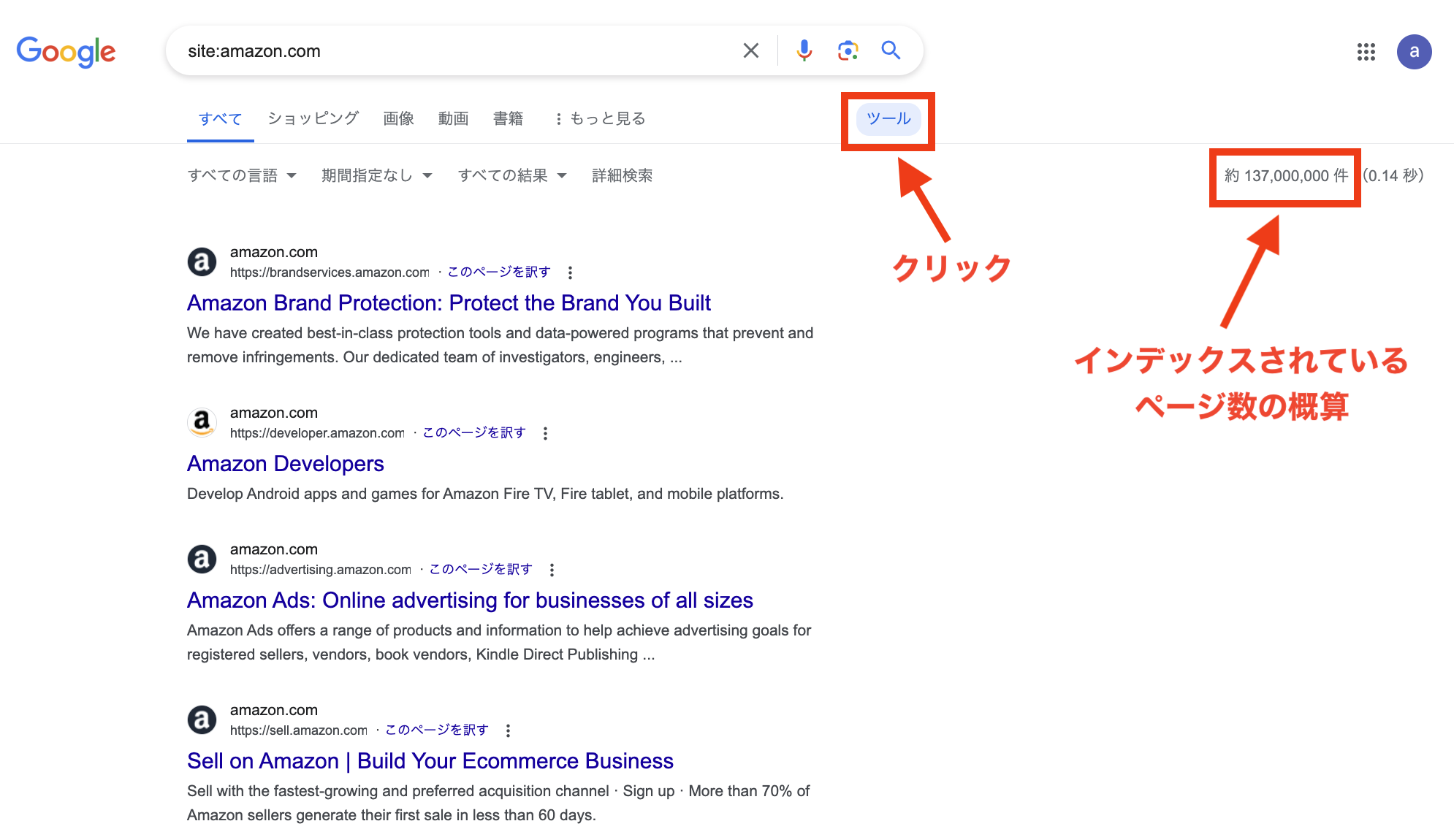
例として、アマゾンのサイトを使って説明します。
記述例
site:amazon.com
このように記述してGoogleで検索すると、2つの情報を得る事ができます。
(1) インデックスされている実際のページリスト
(2) インデックスされているページ数
2013年1月31日現在のアマゾンのサイトにおけるインデックス数は「約 245,000,000 件」です。
しかし、これを見た多くの人は「約 245,000,000件の検索結果をソートしたい」と考えるより、「単純に多いな」、と感じるだけだと思います。
それじゃ、どうやってこの膨大にあるGoogleのインデックスを掘り下げていけるか、っていうのが今回の記事テーマ。
以下より記述しているのが具体的な「site:」コマンドオプションで、それぞれの使い方に関してコメントしています。
※2024年6月追記
インデックスされているページ数については、デフォルトの検索結果には表示されなくなっています。
検索結果ページの上部タブの右側にある「ツール」をクリックすることで表示させることができます。
2. site:example.com/folder
大量の結果に切り込む最も簡単な方法として、(”/blog”のように)サブフォルダをつけることが挙げられます。
記載方法は、以下の通りルートドメインの最後にフォルダを記述します。
記述例
site:amazon.com/books
単純なコマンドではありますが、もし、自分の管理しているサイトでサイト構成がわかっているならば、クロールの問題発見に使う事が出来ます。
2. site:example.com/folder
大量の結果に切り込む最も簡単な方法として、(”/blog”のように)サブフォルダをつけることが挙げられます。
記載方法は、以下の通りルートドメインの最後にフォルダを記述します。
記述例
site:amazon.com/books
単純なコマンドではありますが、もし、自分の管理しているサイトでサイト構成がわかっているならば、クロールの問題発見に使う事が出来ます。
3. site:sub.example.com
特定のサブドメインを掘り下げたい時はこちら。
site:コマンドの後ろに、サブドメイン全てを記述します。
保有する全てのサブドメインを一括で吐き出すには、「1」のコマンドを記述しますが、こちらのコマンドでは、特定したサブドメインを探るような状況に役立ちます。
記述例
site:local.amazon.com
4. site:example.com inurl:○○
「inurl:」コマンドは、インデックスされているURL内の特定のテキストを検索します。
フルのURLからサブドメインを見つけるのに、「site:」と「inurl:」をペアにして使うことができます。
サブドメインを見つける場合は「3」のコマンドで問題ないと思いますが、「inurl:」は、フォルダやページ/ファイルの名前も含め、
URLのテキストを検索でき、複数の組み合わせも可能なので、特定フォルダやファイルを探す際など、柔軟に使う事ができます。
記述例
site:amazon.com inurl:local
5. site:example.com -inurl:○○
[-]を「inurl:」コマンドの前につけると、特定のテキストを除いた検索を行えます。
この場合、「inurl:local」を「-inurl:local」にかえると、「local」サブドメインを除いた検索ができます。
記述例
site:amazon.com -inurl:local
6. site:example.com -inurl:○○ -inurl:△△ -inurl:××
Googleのコマンドの殆どは組み合わせて検索できます。
「site:example.com -inurl:○○ -inurl:△△ -inurl:××」と検索すれば、「○○」「△△」「××」のテキストを含まないURLのみ返されます。
下記の様に多数の「-inurl:」を繋げれば、「askville.amazon.com」や「fresh.amazon.com」等、知らなかったサブドメインを見つける事もできます。
記述例
site:amazon.com -inurl:www -inurl:local -inurl:aws
7. site:example.com inurl:https
「site:」に直接プロトコル(例えば「https:」「ftp:」など)を記述する事はできません。
しかし「inurl:」には「https:」を記述することができ、Googleでインデックスされている暗号化されたページを確認する事ができます。
記述例
site:amazon.com inurl:https
8. site:example.com inurl:param
URLのパラメータはわずかにページを変更しますが、基本的に価値がない重複ページと認識されます。
そんなページがインデックスされているのかどうかを調べたい時に使います。
例えば、使用している製品の全てのページに印刷バージョンがあり、独自のURLを持っているとしましょう。
記述例
www.example.com/product.php?1234
www.example.com/product.php?1234&print=1
この場合、「print=1」の URLは、通常、同じ内容の印刷用バージョンを示します。
「inurl:」でパラメータを指定し、もし印刷用バージョンのページも多くインデックスされている様であれば、印刷ページをNOINDEXする、カノニカルタグで正規化する等の対策が考えられます。
重複ページに関して詳しい記事はこちら。
※1:http://www.seomoz.org/blog/duplicate-content-in-a-post-panda-world
検索結果で並び順、フィルター、ページ数等のパラメータを使用しているなら、「inurl:」にパラメータ名を指定して検索できます。
記述例
site:amazon.com inurl:ref
上の例では「inurl:ref」は「ref」を含むが、URLパラメータを含まないURLを多く返しています。
一般的なワードと重複するパラメータ検索をする場合は注意して下さい。
9. site:example.com -inurl:param
どのくらい多くのページがソートされずにインデックスされているのか、又、どれくらい多くの製品ページをGoogleが色やサイズを選択する事なくインデックスしているのか知りたい場合に使います。
「-inurl:」に除きたいパラメータをつけて検索します。
含めたいパラメータ/含めたくないパラメータを指定し、「inurl:」と「-inurl:」を繋げて用いることも可能です。
ECサイトで使うことが多いです。
記述例
site:amazon.com -inurl:ref
10. site:example.com テキスト
普通のテキストを「site:」に結び付ける事もできます。
これはサイト内の全ページのコンテンツを検索します。
ただし、複数のテキストが存在する場合、論理的には[AND]となりますが、確実ではありません。
Googleはすべてのテキストをマッチさせようとしますが、ページ内で点在していたり、一部のテキストのみを含むようなサイトが検索されてしまいます。
その為、下記の例では「free Kindle books」以外も検索されてしまいます。
記述例
site:amazon.com free kindle books
11. site:example.com “テキスト”
確実にテキストにマッチさせたい場合は、引用符で囲みます。
「10」の例では「free Kindle books」以外も含んでいましたが、下記の例では完全一致した単語を含むページが検索されます。
記述例
site:amazon.com “free kindle books”
12. site:example.com/folder “テキスト”
これは、前述した「2」のコマンドとテキストを組み合わせて検索できます。
例えば、重複を探すことを目的とする検索において、ブログや店のページなど範囲を狭めるときに利用できます。
DVDカテゴリのハリーポッターではなく、本カテゴリのハリーポッターを探したい時は、下記の様に記述します。
記述例
site:amazon.com/books “harry potter”
13. site:example.com this OR that
テキストの条件を絞り込みたい場合は、[or]を使用できます。
この場合では、「this」「that」いずれか(または、両方)を含むインデックスされたページを探す事ができます。
探したいテキストを忘れてしまい不確かな場合に、キーワードをいくつか指定して検索するのに役立ちます。
記述例
site:amazon.com edward or jacob
14. site:example.com “top * ways”
アスタリスク「*」は、Googleの検索において不特定のテキストに置き換わるワイルドカードとして使用できます。
ブログで「Top X」を全て見つけたい時、ブログのフォルダを対象に「Top *」とテキストを絞りこめます。
記述例
site:amazon.com “top * books”
ワイルドカード「*」は1文字、または、複数文字をマッチさせます。
なので、「top * books”」の場合は、「Top 100 Books」「Top Wedding Planning Books」共にマッチします。
15. site:example.com “top 5..40 ways”
数字を特定の範囲で絞りたい場合、「X..Y」を使用します。
「X..Y」はXからYの範囲の値にマッチするページを返します。
製品IDから価格等、ページ上の様々なデータの範囲を指定する時に使う事ができます。
下記の例ではアマゾンtop5~top40までの小説を探す事ができます。
記述例
site:amazon.com “top 5..40 novels”
16. site:example.com ~word
チルダ「~」は指定したキーワードと関連する文言を検索できます。
Googleが関連があると考える文言で、より広く検索できます。
下記の様に、アマゾン内を「management」に関連するキーワードで検索したいとき、コマンドに「~management」を付け加えます。
検索結果には、Googleが関連があると考えている「Leadership」「Manage」「Control」等も返されています。
記述例
site:amazon.com ~management
17. site:example.com ~word -word
特定の文言を除く「-」を用いることで、指定した文言は含まず、指定した文言の概念に関連のあるページを検索できます。
下記の例では、「management」は含まず、「management」に関連する「Leadership」「Manage」「Control」等のみが返されます。
記述例
site:amazon.com ~management -management
18. site:example.com intitle:”テキスト”
「intitle:」はtitleタグ内のテキストのみにマッチングを絞り込みます。
SEOではよく使うコマンドですが、重複ページがないかどうか等の確認に便利です。
記述例
site:amazon.com intitle:”harry potter”
19. site:example.com intitle:”text * here”
「intitle:」と「12」-「17」を組み合わせてコマンドを使用できます。
下記ではページタイトルのテキストのみに限定し、「14」のワイルドカードによる検索をしています。
これにより、タイトル内に「The * Games」のテキストが存在するページを検索できます。
記述例
site:amazon.com intitle:”the * games”
「intitle:」の後には文言の引用符をつけることを忘れないでください。
そうしなければ、Googleは通常のテキスト検索と1KWのみのタイトル検索を行ってしまいます。
例えば、”intitle:text goes here”と記述した場合、タイトル上の”text”とページ内の”goes” と “here”を検索します。
20. intitle:”テキスト”
これは「site:」との組み合わせのコマンドではありませんが、役に立つので含めています。
「intitle:」の後に引用符で囲んだテキストを記述する事で、コピーされたサイトを見つける事ができます。
他のサイトが自分のコンテンツをコピーしていると疑った事はありませんか?
これは、コンテンツを盗んだ人をみつけるのに役立ちます。
又、記事のタイトルがユニークであることを確認するのに便利な方法でもあります。
記述例
intitle:”fifty shades of grey”
21. “テキスト” -site:example.com
サイトをもう少し絞り込んで検索したい場合、「-site:」を使い、(自サイトも含め)同じドメイン上の同類ページを除外できます。
これは、単純なテキスト検索、又は「20」のように「intitle:」と組み合わせて使えます。
自分のサイトを除外し、競合他社の状況確認に使ったりします。
記述例
“amazon kindle” -site:wikipedia.org
22. site:example.com intext:”テキスト”
「intext:」では、文書の本文内のキーワードを検索しtitleタグを検索しません。
本文内のテキスト検索なので、おのずとtitleにも含まれている事がありますが、この場合の検索対象は本文内です。
しかし、「intext:」ではURL内のキーワードも検索しているみたいですね。
記述例
site:amazon.com intext:”best book ever”
23. site:example.com “テキスト” -intitle:”テキスト “
この場合、「22」と同じかなと思ってしまいますが、微妙な違いがあります。
「intext:」の場合は、Googleはtitleタグを無視しますが、具体的なキーワードでは除外されません。
検索結果で特定のタイトルのキーワードを除外したい場合は、”-intitle:”を使用します。
記述例
site:amazon.com intext:”best book ever” -intitle:”best book ever”
24. site:example.com filetype:pdf
「inurl:」コマンドの欠点の一つは、それがURL内の任意の文字列に一致するということです。
例えば、「inurl:PDF」という検索を行うと、「/guide-to-creating-a-great-pdf」という名前のページが検索されます。
「filetype:」を使う事で、ファイル拡張子を指定できます。
下記例ではアマゾンのエクセルファイルのみ返してくれます。
記述例
site:amazon.com filetype:xls
25. site:.edu “テキスト”
最後に、トップレベルドメイン(TLD)のみをターゲットにした検索です。
※トップレベルドメイン(TLD)の1つで、アメリカ合衆国の教育機関のドメイン。eduは “education” の意味です。
いかがでしたでしょうか。
「site:」コマンドと言っても様々種類があると分かったと思います。
サイトの問題点発見や競合調査、検証に使えるのでぜひ試してみて下さい。
Googleコマンドにはその他コマンドが色々とあるのですが、長くなるので次の機会にご紹介したいと思います。
「site:」コマンドを使用する際の注意点
SEOmozの記事についてはここまでですが、補足として、「site:」コマンドを使用するうえでの注意点についても補足できればと思います。
注意点①:「インデックスされていることを確認する」なら「Search Console」が確実
「site:」コマンドを特定のURLのインデックス状況を確認する目的で使う場合もあるかと思います。
ただし、Googleの公式ドキュメントによるとインデックスされていても表示されない場合もあるとのこと。
URL が Google のインデックスに登録されていれば、その URL に関連する site: クエリの検索結果に表示される可能性がありますが、常に表示される保証はありません。site: クエリで URL が表示されない場合は、URL 検査ツールを使用して、インデックス登録が可能な URL であることを確認し、URL のインデックス登録リクエストを送信してください。また、クエリが正しいことを入念に確認してください。site:https://www.example.com の検索結果は site:https://example.com/ の検索結果と同じではありません。
「site:」コマンドで表示されない場合は、「URL検査ツール」使うように、と書かれています。
「URL検査ツール」はGoogleが無償で提供しているWebマスター向けのサイト管理ツール「Search Console(サーチコンソール)」の機能です。
上部検索バーに対象のURLを入力してエンターを押すと、該当URLがすでにインデックスされているか、また、インデックス可能な状態か、ということも表示されます。
ページがインデックスされているかを確実に知るのであれば、この機能を活用しましょう。
なお、インデックスされていない場合は、「インデックス登録をリクエスト」をクリックすることで、Googleにインデックス登録をリクエストできます。
注意点②「インデックスされているページ数」は、全ページを網羅していない
「site:」コマンドで、「インデックスされているページ数」が表示されますが、こちらも大まかな数値で正確ではないことに注意しましょう。
Google公式のドキュメントには以下のような記載があります。
返される URL のリストは網羅的ではありません。大規模なサイトでは、サイト内のすべての URL が結果に表示されることは期待できません。クエリで限定的なプレフィックスを指定すると、幅広いプレフィックスよりも多くの結果が得られます。
専門用語が多くわかりづらいですが、要は大規模なサイト(ニュースサイトや大手通販モールサイトなど)の場合はすべてのURLが表示されることはない、ということ。
上記のオプションを使用することで検索条件を厳密にすると、その検索条件についてはドメイン全体で検索した時よりも、多くのページがヒットする可能性があります。
「site:」コマンドを使用する際には、これらの注意点を踏まえたうえで活用するようにしてください。
当サイトではこの他にもWebに関するお役立ち情報を多数ご紹介しています。
Web担当者の方、デジタルマーケティングに興味がある方はぜひご覧ください。
広告運用やSEO、解析・Web製作など、当社はWebに関わるベストソリューションをご提供しています。お悩み・ご相談も受け付けておりますので下記のボタンからお気軽にご連絡ください。
SEOにお困りなら【無料SEO診断】
株式会社デジタルアイデンティティでは、創業から14年以上、SEO対策に注力してきました。
検索エンジンをハックするようなブラックハットな手法に頼ることなく、Googleの推奨に沿ったホワイトハットな手法で上位表示を実現してきました。
そんな弊社のSEOナレッジを50以上の項目に落とし込んだSEO診断を無料でご提供しています!
(毎月先着10社様限定とさせていただいています)

無料SEO診断はこんな方におすすめ!
- SEO対策をどこから始めればいいかわからない…
- 自社でSEO対策をしているが思うように順位が上がらない…
- 他社にSEO対策を依頼しているがセカンドオピニオンが欲しい…
- なぜ競合サイトの検索順位が高いのか知りたい…
- 現在のSEO対策が正しいのか確認したい…
弊社の無料SEO診断でわかること
- 現在のSEO評価
- SEO項目ごとの改善方法
- SEO項目ごとの優先度
正しい現状認識は、SEO対策で効果を出す上で何よりも重要です。
自社のSEO対策について、少しでも気になる方は以下のリンクからお気軽にお申し込みください。







![[無料]成果に繋がる!具体策が分かる!SEOセミナー 「初心者向け」「コンテンツSEO」「サイト内部施策」 詳しくはこちら](https://digitalidentity.co.jp/blog/wp/wp-content/themes/gorgeous_tcd013-child/img/common/bnr/sidebar-seo-seminar.jpg)